What is a robots.txt?
The robots.txt is a file that helps dictate where a crawler, like a search engine bot, can and cannot crawl. It’ll vary depending on the site you’re working with but there may be areas such as login pages, paginated resources, or various backend URLs that you don’t want spilling into the SERPs, or search engine results pages.
Why is a Robots.txt Important?
A website has a crawl budget, as in, a search engine gives your site an allowance from which it can crawl your site and make sense of all it is seeing. The robots.txt file helps manage a website’s crawl budget through the directives outlined in the file.
You want to make sure you tell search engines that there are site pages or sections that might be more important to crawl than others. Or, conversely, there are site pages / sections that are completely off limits.
If your site is fairly large or prone to auto-generating various URLs, you might find that you may eat up a lot of the crawl budget through the use of pagination.
Robots.txt Format
The robots.txt file is primarily made up of 2 pieces of syntax: User-agent: and Disallow:
User-agent:
A user-agent is the target search engine bot for the robots directives.
To understand web page content, search engines use pieces of software called bots to scour the web. These bots are called upon in the robots.txt file with the User-agent: line.
If you want to provide the same directives to all bots, that is, all search engines, you’d use the below User-agent: line.
User-agent: *Where * acts as a directive to capture “all” bots.
You can also specify directives for individual bots. For example, you can have directives for Googlebot and Bingbot, Google and Bing search engine bots, respectively.
User-agent: GooglebotUser-agent: BingbotFor other common bot user-agents, see below.
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: Yandex
Disallow: or Allow:
There are 2 common directives that guide which directories / subfolders search engines are able to access.
- Disallow: Discourages search engines from accessing a location
- Allow: Encourages search engines to access a location
The Disallow: and Allow: directives are the main components that guide the crawling behavior of search engines. With both, you’re able to efficiently use a bot’s crawl budget. Conversely, if neither are used at all, crawl budget can be severely depleted.
Sitemap:
Another common directive is the Sitemap: syntax.
The Sitemap: tells search engines where a bot will be able to find a site’s sitemap files. The sitemap files serve as a collection of all the URLs found on a site, which can then be uploaded to Google Search Console or Bing Webmaster Tools.
Below are the Sitemap directives in my robots.txt file.
Sitemap: https://www.edwindanromero.com/sitemap_index.xml
Sitemap: https://www.edwindanromero.com/post-sitemap.xml
Sitemap: https://www.edwindanromero.com/page-sitemap.xml
Sitemap: https://www.edwindanromero.com/category-sitemap.xmlRobots.txt Example
I’m looping in my robots.txt to show what I’m blocking and allow search engines to access.
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.edwindanromero.com/sitemap_index.xml
Sitemap: https://www.edwindanromero.com/post-sitemap.xml
Sitemap: https://www.edwindanromero.com/page-sitemap.xml
Sitemap: https://www.edwindanromero.com/category-sitemap.xmlThe above states that the directives apply to all search engines,
User-agent: *The directories that are disallowed are,
Disallow: /wp-admin/And the directories that are allowed are,
Allow: /wp-admin/admin-ajax.phpAnd that my sitemap files can be found here,
Sitemap: https://www.edwindanromero.com/sitemap_index.xml
Sitemap: https://www.edwindanromero.com/post-sitemap.xml
Sitemap: https://www.edwindanromero.com/page-sitemap.xml
Sitemap: https://www.edwindanromero.com/category-sitemap.xmlTesting your Robots.txt
To help assess the entire breadth of the URLs you want to block in robots.txt, you will want to perform a crawl using a crawler such as Screaming Frog.
Screaming Frog will allow you to crawl with the current robots.txt in place or use a custom robots.txt. I found using a custom robots.txt is a great way to test directives without having to upload them to your site.
Ensure your crawler obeys the intended robots.txt file.

Additionally, target a specific user-agent, or bot. I typically use Googlebot’s user-agent to assess how the bot picks up on URLs across the site with the robots.txt file in place.
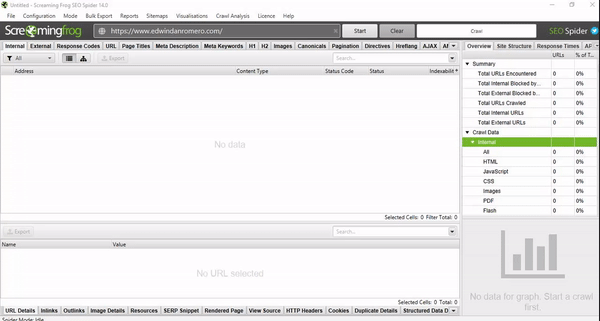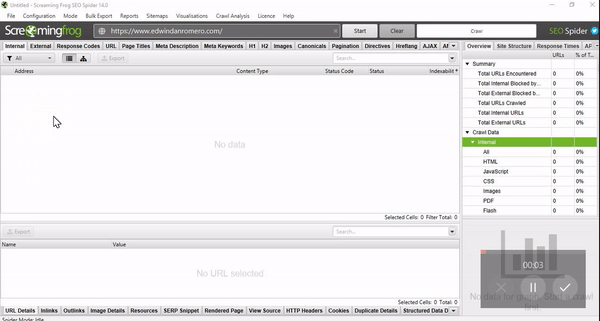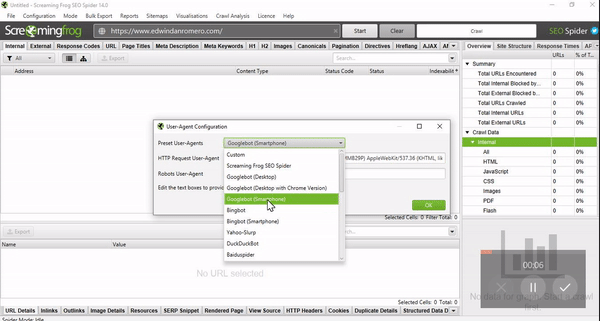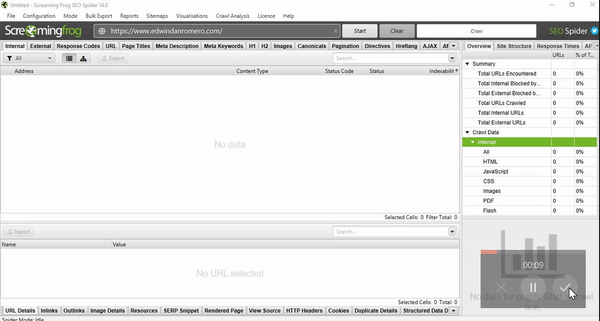
Upon crawling your site with Screaming Frog, underneath an “Indexability” column, the tool will tell you if a web page is “Non-Indexable” because it was Disallowed.

Although there are “Non-Indexable” URLs, my crawl didn’t identify any that were being blocked by robots.txt. Your crawl might be different depending on the site structure.
If you want to check whether the robots.txt will block a specific URL without crawling an entire site, you can use the Custom robots.txt feature. I will use my current robots.txt file and test if one of my blocked URLs is accessible.
I pulled in my current robots.txt, then I tried crawling /wp-admin/ but was unable to because it was Disallowed.

Robots.txt Templates
The below links are resources for webmasters that typically find themselves looking for an out-of-the-box robots.txt template for a specific content management system, or CMS.
When working with a specific content management system, the infrastructure may be built in such a way, you can lean on a templated robots.txt that can help block URLs that may otherwise be unwanted pages into the SERPs.
If your specialization isn’t SEO but you have to add a robots.txt in accordance with your SEO Project Plan and unsure where to start with creating the file, I hope the templates below serve as a quick resource for copying and pasting files.





